GenSeq: MLO for Text Augmentation
Text augmentation is an effective technique in alleviating overfitting in NLP tasks. In existing methods, text augmentation and downstream tasks are mostly performed separately. As a result, the augmented texts may not be optimal to train the downstream model. To address this problem, we propose a three-level optimization framework to perform text augmentation and the downstream task end-to- end. The augmentation model is trained in a way tailored to the downstream task. Our framework consists of three learning stages. A text summarization model is trained to perform data augmentation at the first stage. Each summarization example is associated with a weight to account for its domain difference with the text classification data. At the second stage, we use the model trained at the first stage to perform text augmentation and train a text classification model on the augmented texts. At the third stage, we evaluate the text classification model trained at the second stage and update weights of summarization examples by minimizing the validation loss. These three stages are performed end-to-end. We evaluate our method on several text classification datasets where the results demonstrate the effectiveness of our method.
Introduction
Data augmentation is an effective technique for mitigating the deficiency of training data and preventing overfitting. In natural language processing, many data augmentation methods have been proposed, such as back translation, synonym replacement, random insertion, and so on. In existing approaches, data augmentation and downstream tasks are performed separately: Augmented texts are created first, then they are used to train a downstream model. The downstream task does not influence the augmentation process. As a result, the augmented texts may not be optimal for training the downstream model.
In this paper, we aim to address this problem. We propose an end-to-end learning framework based on multi-level optimization, which performs data augmentation and downstream tasks in a unified manner where not only augmented texts influence the training of the downstream model, but also the performance of downstream task affects how data augmentation is performed.
In our framework, we use a text summarization model to perform data augmentation. Given an original text t with class label c, we feed t into the summarization model to generate a summary s. We set the class label of s to be c. (s,c) is treated as an augmented text-label pair of (t,c). The motivation of using a summarization model for text augmentation is two-fold. First, the major semantics of an original text is preserved in its summary; therefore, it is sensible to assign the class label of the original text to its summary. Second, the summary excludes non-essential details in the original text; as a result, the semantic diversity between the summary and the original text is rich, which well serves the purpose of creating diverse augmentations. The summarization model is trained on a summarization dataset where is an original text and is the corresponding summary. For the downstream task, we assume it is text classification. We assume there is a text classification training set where is an input text and is the corresponding class label, and there is a text classification validation set .
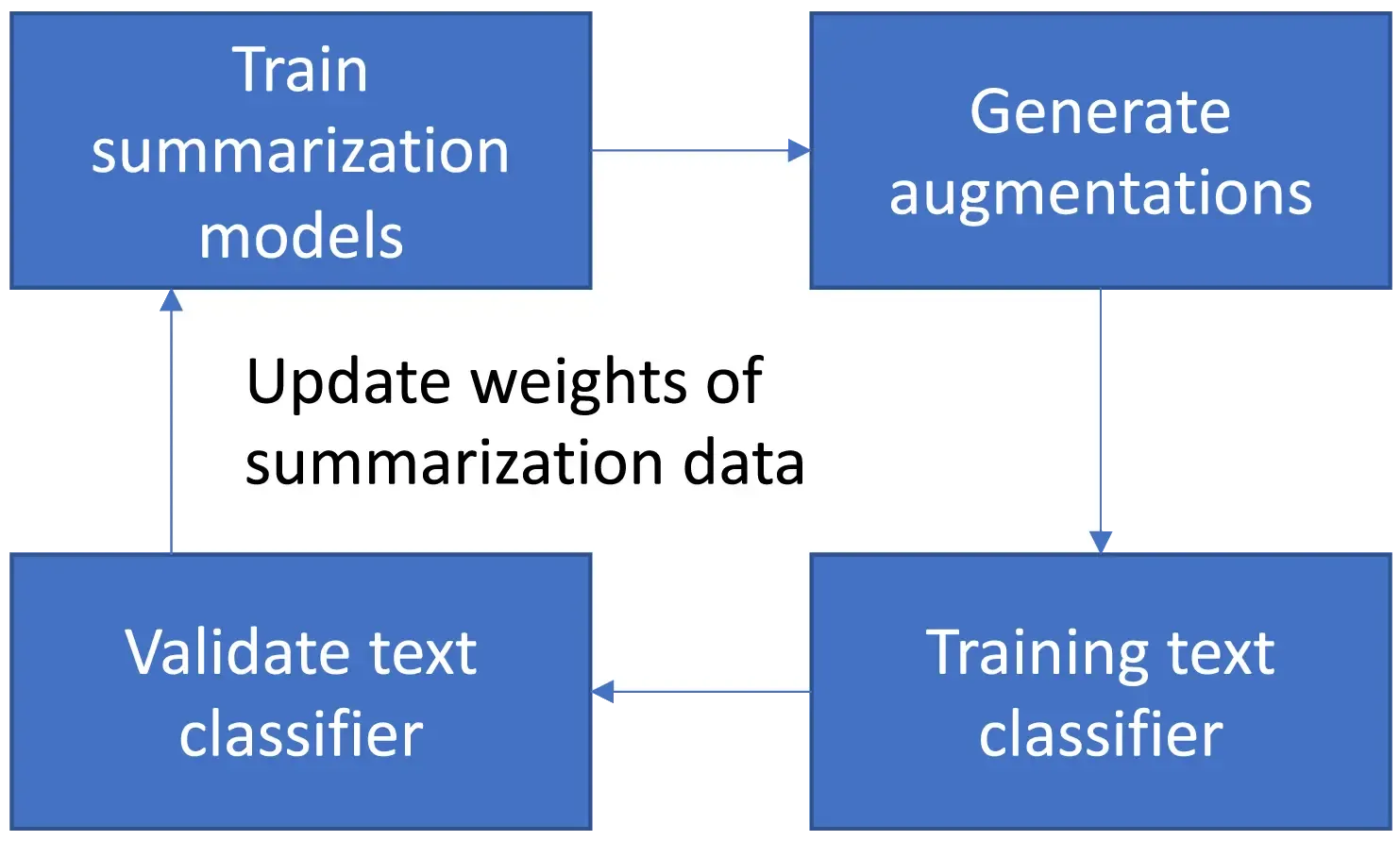
Our framework consists of three learning stages that are performed end-to-end. We train a text summarization model G on the summarization dataset at the first stage. Considering a domain difference between the summarization data and text classification data, we associate each summarization training pair with a weight . A smaller indicates a large domain difference between this summarization pair and the text classification data, and this pair should be down-weighted during the training of the summarization model. These weights are tentatively fixed at this stage and will be updated later. At the second stage, we use the trained summarization model to perform text augmentation for the classification dataset and train a text classification model on the augmented and original datasets. At the third stage, we validate the classification model trained at the second stage and update weights of summarization training examples by minimizing the validation loss. The three stages are performed end-to-end where they mutually influence each other. We evaluate our framework on several text classification datasets. Various experiments demonstrate the effectiveness of our method.
The major contributions of this work include:
-
We propose a three-level optimization framework to perform text augmentation in an end-to-end manner. Our framework consists of three learning stages that mutually influence each other: 1) training text summarization model; 2) training text classification model; 3) updating weights of summarization data by minimizing the validation loss of the classification model.
-
Experiments on various datasets demonstrate the effectiveness of our framework.
Related Work
Data Augmentation in NLP
As an effective way of mitigating the deficiency of training data, data augmentation has been broadly studied in NLP. Sennrich et al. proposed a back translation method for data augmentation, which improves the BLEU scores in machine translation (MT). The back translation technique first converts the sentences to another language. It again translates it back to the original language to augment the original text.
Fadaee et al. propose a data augmentation method for low-frequency words. Specifically, the method generates new sentence pairs that contain rare words. Kafle et al. introduce two data augmentation methods for visual question answering. The first method uses semantic annotations to augment the questions. The second technique generates new questions from images using an LSTM network. Wang and Yang propose an augmentation technique that replaces query words with their synonyms. Synonyms are retrieved based on cosine similarities calculated on word embeddings. Kolomiyets et al. propose to augment data by replacing the temporal expression words with their corresponding synonyms. They use the vocabulary from the Latent Words Language Model (LWLM) and the WordNet.
Şahin and Steedman propose two text augmentation techniques based on dependency trees. The first technique crops the sentences by discarding dependency links. The second technique rotates sentences by tree fragments that are pivoted at the root. Chen et al. propose augmenting texts by interpolating input texts in a hidden space. Wang et al. propose augmenting sentences by randomly replacing words in input and target sentences with words from the vocabulary. SeqMix proposes to create augments by softly merging input/target sequences.
EDA uses four operations to produce data augmentation: synonym replacement, random insertion, random swap, and random deletion. Kobayashi proposes to replace words stochastically with words predicted by a bi-directional language model. Andreas proposes a compositional data augmentation approach that constructs a synthetic training example by replacing text fragments in a real example with other fragments appearing in similar contexts. Kumar et al. apply pretrained Transformer models including GPT-2, BERT, and BART for conditional data augmentation, where the concatenation of class labels and input texts are fed into these pretrained models to generate augmented texts. Kumar et al. propose a language model-based data augmentation method. This approach first finetunes a language model on limited training data, then feeds class labels into the finetuned model to generate augmented sentences. Min et al. explore several syntactically informative augmentation methods by applying syntactic transformations to original sentences and showed that subject/object inversion could increase robustness to inference heuristics.
Bi-level Optimization
Many NLP applications are based on bi-level optimization (BLO), such as neural architecture search, data selection, meta learning, hyperparameter tuning, label correction, training data generation, learning rate adaptation, and so forth. In these BLO-based applications, model parameters are learned by minimizing a training loss in an inner optimization problem while meta parameters are learned by minimizing a validation loss in an outer optimization problem. In these applications, meta parameters are neural architectures, weights of data examples, hyperparameters, and so on.
Method
This section proposes a three-level optimization framework to perform end-to-end text augmentation.
Overview
We assume the target task is text classification. We train a BERT-based text classifier on a training set where is an input text and is the corresponding class label. Meanwhile, we have access to a classification validation set . In many application scenarios, the training data is limited, which incurs a high risk of overfitting. To address this problem, we perform data augmentation of the training data to enlarge the number of training examples. We use a text summarization model to perform data augmentation. Given an original training pair , we feed the input text into the text summarization model and get a summary . Because preserves the major semantics of , we can assign the class label of to . In the end, we obtain an augmented training pair . This process can be applied to every original training example and create corresponding augmented training examples.
To enable the text summarization model and the text classifier to influence and benefit from each other mutually, we develop a three-level optimization framework to train these two models end-to-end. Our framework consists of three learning stages performed in a unified manner. At the first stage, we train the text summarization model. At the second stage, we use the summarization model trained at the first stage to perform text augmentation and train the classifier on the augmented examples. At the third stage, we evaluate the classifier on a validation set and update weights of summarization training examples by minimizing the validation loss. Figure 1 shows an overview of our framework. Next, we describe the three stages in detail.